
Strojové učení
Někdy také jako umělá inteligence
Strojove ucenie sa stalo neoddeliteľnou súčasťou moderného sveta a ci uz to viete alebo nie, pravdepodobne pohana aplikacie, ktore pouzivate kazdy den. Virtualni osobni asistenti, ako Siri a Alexa, doporucovacie algoritmy od Netflixu, YouTubu ci Spotify, klasifikovanie spamu a validnych e-mailov, rozpoznavanie tvari od Facebooku, klinicke dignozy od IBM, autonomne auta od Tesly ci Waymo, jazykove preklady Google Translate, az po programy schopne porazat ludi v sachu ci go ako AlphaZero.
Umělá inteligence a strojové učení
Umelá inteligencia je siroky pojem ktory popisuje schopnost pocitacov/strojov riesit problemy, ktore normalne vyzaduju ludsku inteligenciu. Strojove ucenie je potom vo svojej podstate druh umelej inteligencie, ktory je zalozeny na samouceni z dat ktore umoznuje pocitacom riesit specificke problemy bez toho aby im boli explicitne poskytnute inštrukcie ako na to.
Historie strojoého učení
Strojove ucenie nie je v žiadnom prípade novy fenomen. Neurónové siete, ako prominentna metoda, boli po prvy krat predstavene ako koncept v akademickom clanku v roku 1943.
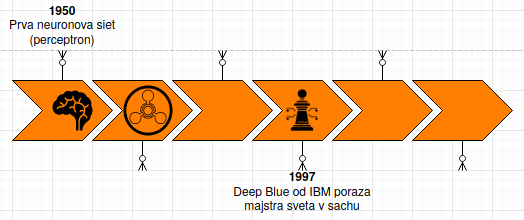
To čo je dnes nove a to co stoji za uspechmi strojoveho ucenia je rast vypocetnych moznosti ktore su k dispozicii. Bez velkeho mnozstva dat a bez dostatočnej vypocetnej kapacity by boli tieto modely totiz akurat teoretickou hračkou akademikov.
Příklad s koupí domu
Ako pouzivame strojove ucenie u nas? Najlepsie si to asi ukazeme na hypotetickom priklade Karla.[1]
Karel si chce kupit akciu Tesly na burze. V dnešnej dobe snad nie je nic lahsie, otvorit si ucet u brokera a 2-krat kliknut. Karel, analytik srdcom, ale vie, ze na to aby to bola dobra investicia je nutne aby cena akcie v bola v budúcnosti vyššia ako je teraz[2]. Napriek tomu, ze si precital vela clankov o svetlej buducnosti elektrickych autonómnych aut, spravy o genialite Elona Muska a analyz tzv. “stock-pickerov”[3], nie je presvedceny. Rovnako totiž vie, ze ludia sa casto mylia, podliehajú kadejakym popudom a keby mali realnu schopnost spolahlivo predikovať vyvoj akcii, tak by rozhodne nemuseli pisat ziadne clanky. Rozhodne sa preto nazbierať si vlastne data. Ake data ma ale zhanat? Ked si v minulosti kupoval dom, zisťoval si nielen udaje o dome samotnom, ale aj o domoch v sirokom okoli, aby spravil co najlepsie rozhodnutie. Po kratkej analyze dat z realitnych portalov vtedy zistil, ze cena domu závisí na jeho lokalite, stave budovy, rozlohe pozemku a mnohych inych.
V termínoch štatistiky a strojoveho ucenia, Karel objavil regresiu. Velmi zjednodusene, linearny regresny vztah sa da zapisat ako nasledovna rovnica.
C= λ0+λ1z1+...λkzk
C je cena nehnutelnosti, z1,...zk su premenne od ktorych sa cena odvija by napriklad mohla byt rozloha pozemku, napriklad vzdialenost do najblizsieho krajskeho mesta, atd. V Karlovom jednoduchom modely ku každej premennej prilieha jeden koeficient, tie su znacene ako λ0,...λk .
Tieto koeficienty su klucove a hovoria aku vahu jednotlive premenne zohravaju v tom ako je dom ohodnoteny[4]. Ukazkovym koeficientom by bol ten, pred premennou rozloha pozemku (m^2). Ten by nam v skratke hovoril, ako sa meni hodnota domu pri roznych m^2, ked su ostatne premenne nezmenené/zafixované/rovnake. Inými slovami, povedal by nam aka je cena za meter štvorcový!
[1] https://vas3k.com/blog/machine_learning/
[2] Alebo aby Tesla vyplatila dividendu vacsiu nez by bol pripadny pokles ceny.
[3] Investori ktory stavkuju na jednotlive firmy typicky na zaklade manualnej a fundamentalnej analyzy podkladovej spolocnosti.
[4] Kontrolujuc pri tom vplyv ostatných premenných v modeli.
Jak je to v případě akcií?
V pripade akcii by to nemuselo byt velmi odlisne! Pouceny z pripadu s nakupom domu, rozhodne sa postupovat obdobne. Vie vsak, ze je to pravdepodobne komplikovanejsie, zaroven vsak mnohe otazky su podobne. Rovnice, kterou jsme použili při výpočtu hodnoty domu, se dá také zobrazit jako graf. V případě lineární regrese o jedné proměnné by předpověď výnosu akcií na základě jedné charakteristiky vypadala takto.
(vložit graf linear_annotated)
Ako ale ziskat hodnoty koeficientov, co nam povedia ktora akcia má akú hodnotu na zaklade hodnot jednotlivych premenných? A ake vsetky premenne zahrnut? Karel vie, ze aj v pripade domu to je komplikovanejsie a faktory ine ako tie co zvazil mali urcite taktiez vplyv, napr. rusna cesta rovno pod oknom, skladka za rohom, kriminalita v regióne, apod.
Všetko poporiadku. Na to aby človek zistil, ako oceňovať domy, musel by vidiet/preskumat vela domov, ake mali charakteristiky, za koľko sa predavali. Taktiez by to musel robit nejaku dobu, inak by sa totiž obchodovali pocas hospodarskej krizy a inak pocas ekonomického boomu.
Podobne je to aj s akciami, akurat komplikovanejsie. Pocet premenných, ktore by mohli mat vplyv na hodnotu akcie je radovo vyssi. Kazda verejne obchodovana firma zverejňuje svoje ucetne vykazy, ma istu poziciu medzi svojou konkurenciou, pohybuje sa v istom regulačnom prostredi, atd. Ak ma mat Karel vobec nejaku sancu, tak vie, ze potrebuje veľa informácii/dat a potrebuje ich pre co najvacsiu vzorku firiem, aj tych co uz davno neexistuju.
Kolko stal Enron pred bankrotom, aky dlh mal Lehman Brothers, co si mysleli analytici o Amazone v 1999tom, ake bolo HDP Britanie za posledných 5 rokov, kolko akcii Microsoftu sa zobchodovalo na Nasdaqu posledny den predchádzajúceho roku.
Mnoho dat vsak neznamena automaticky mnoho kvalitných dat. Velka cast z nich su bezcenne pre predikcne ucely. Jak víme, která data jsou bezcenná? Něco nám může napovědět ekonomická teorie nebo akademický výzkum. Jinak je ale poznáme tak, že je zahrneme do jednoho modelu společně s kvalitními daty a uvidíme, že statisticky v tomto modelu nemají žádný význam. Musíme si ale přitom dát pozor na dvě věci. Pokud bychom v modelu neměli kvalitní data, nebo pokud bychom nepoužili správně statistické metody, mohlo by se stát, že bezcenná data budou vypadat jako kvalitní. Dopustili bychom se chyby zvané falešná korelace. Příkladem falešné korelace je následující graf, na kterém to vypadá, že jsme objevili zásadní proměnnou pro určení ceny akcie Apple: počet doktorátů z chemického inženýrství udělených v USA. Samozřejmě jsme neobjevili nic a výsledek je dílem náhody. Proti falešné korelaci existuje jednoduchá obrana: kvalitní statistická analýza a správné použití metod strojového učení.
(vložit graf spurious.pdf)
Naštěstí v případě cen akcií nemusíme po proměnných pátrat ve tmě. V pripade hodnotenia firiem a predikovania vynosov akcii existuje celý vedecky obor, ktory sa zaobera otazkou na akych premenných zalezi. V preklade sa vola, adekvátne k svojej náplni, “ocenovanie aktiv”[1], anglicky asset pricing. Za svoju viac ako 40-rocnu historiu sa v ňom naakumulovalo stovky premenných, ktoré by mali vysvetlovat rozdielne hodnoty vynosy verejne obchodovaných firiem.
10 000-ky firiem, 10tky rokov, 100ky premenných zalozenych na 1000kach povodnych udajoch.
Taketo mnozstvo dat vyzaduje strojovy pristup a to nie hocijaký. Excel zamrza, bezny pocitac nestiha. Karel si tedy pořídí výkonný počítač (několik výkonných počítačů), a napíše kód, který na rozdíl od Excelu nespadne, až to množství dat uvidí. Jeho cílem není zkoumat historická data, ale využít je k tomu, aby predikoval ktore akcie maju vyssie budouci vynosy.
O datach, ktore pouzivame na predikciu my sa mozete docitat viacej tu.
Karel ale zjistí, výkonný počítač a vela dat nestačí. Zjistí totiž, že jeho lineární regrese, kterou používal pro ocenění domu, se v tom obrovském množství dat o akciích ztrácí. Co teď? V čem spočívá ten rozdíl mezi domy a akciemi, který působí, že model přestal fungovat? Důvod je, že v pripade linearnej regresie, ktoru ste videli pri ocenovani domu, bol vztah linearny a pocet premennych v modeli bol relativne maly, zatímco u akcií je proměnných mnoho a vztahy mezi nimi nejsou lineární.
Jinými slovy, v případě jedné proměnné nevypadá svět akcií tolik jako rovná čára, ale spíše jako křivka.
(vložit graf spurious.pdf)
Navíc, jak už jsme viděli, proměnné (charakteristiky) nejsou dvě, ale jsou jich stovky!
Na predikncy ukol takehoto razu je potreba pokrocilejsie nastroje. Prediktivnych modelov, ktore sa daju pouzit je viac, od regularizovanych linearnych regresii, napr. Lasso, Ridge alebo Elastic Nets, cez Nahodne stromy az po Neurónové siete. Jednotlive modely su relativne komplikované a na pochopenie vyzaduju znalost matematiky, štatistiky a optimalizacnych algoritmov. Obecny princíp na ktorom stoja je vsak rovnaky. Klucove je, ze nase schopnost ocenovat, nasa schopnost predikovať buduce vynosy je zachytená v odhadnutom “naucenom” modely, konkretne v jeho koeficientoch ( λ0,...λk z prikladu o ocenovani domu) a strukture modelu.
Karel tedy začne používat model strojového učení. Ukáže mu všechna historická data, čímž se model naučí, jaké jsou vztahy mezi charakteristikami firem a jejich budoucím výnosem.
Ten model mu povie, ze pretoze charakteristiky Tesly su X a Y, jej očakávaný vynos je Z.
Karel už může říct, jaké je hodnota Tesly, respektive predikovat její budoucí výnos.
Tato predikcia je zalozena na fakte, ze historicky firmy s podobnými charakteristikami mali podobný vynos.
Znamena to, že si Karel je na 100 procent jistý, že i Tesla bude mat rovnaky vynos?
Samozrejme, že nie. Preto je klucove neinvestovat do jednej firmy, ale celeho portfolia. V tom pripade, aj ked je nasa predikcna schopnost nižšia, ale stale vacsia ako 50%, sme schopny spolahlivo generovať zisky. Pri velkom mnozstve predikcii sa nahodilost pomaly vytraca.
Najlepsie si to predstaviť na pripade nevyvazenej mince. Normalna, vyvazena a ferova minca ma 50% sancu, ze padne hlava a 50% sancu, ze padne znak. Predpokladajme, ze v pripade nasen nevyvazenej mince je pravdepodobnost, ze padne hlava 51% a pravdepodobnost, ze padne znak 49%. Ako zarobit v stavkovani na tuto mincu, ked v pripade hlavy zarobime 10 korun a v pripade znaku prerobime 10 korun? Klucom je hadzat mnoho krat, pripadne hadzat mnoho minci. Pri velkom mnozstve opakovani sa nahodilost pomaly vytraca. Zostava iba profit.
Chcete vědět více? Zeptejte se nás.
Chtete vědět detailněji, jak se jde bránit falešné korelaci? Jaké modely strojového učení používáme? Nebo jak sestavit portfolio tak, aby pracovalo ve váš prospěch podobně, jako hody nevyváženou mincí? Neváhejte kontaktovat našeho šéfa strategie.

Martin Hronec
Head of strategy Pravda Capital
Martin zodpovídá za celou strategii fondu. Dále aktivně pokračuje ve výzkumu a často hovoří na akademických konferencích po celém světě. Martin se stal partnerem společnosti Pravda Capital v roce 2018.